- 01.12.2021
- Kategorie Sonstiges
Wissenschaftliche Prinzipien in den Digital Humanities Teil 2
von NORDfor
Methodenbewusstsein
Von Sven M. Kraus, Ingrid M. Heiene, Balduin Landolt, Elisabeth Magin
Die vorliegende Reihe von Blogposts ist das Ergebnis eines Workshops »Advancing Digital Humanities in Old Norse Studies« , der vom 03. bis 05. Juli 2019 am Nordeuropa-Institut der Humboldt-Universität zu Berlin stattfand. Organisiert von Sven Kraus wurde der Workshop großzügig gefördert von der derzeitigen Inhaberin der Henrik-Steffens-Gastprofessur, Prof. Dr. Marie-Theres Federhofer.
Anlass des Workshops war das Bedürfnis, sich für das Aufgleisen eigener Projekte mit anderen Forschenden austauschen zu können. An dem Workshop nahmen fünf Nachwuchsforschende (Sven M. Kraus, Ingrid M. Heiene, Balduin Landolt, Elisabeth Magin und Jade J. Sandstedt) mit Projekten aus den Fachbereichen Runologie/Archäologie, diachrone generative Syntaxforschung, korpusbasierte historische Phonologie, stilometrische Handschriftenkunde und mittelalterliche Kulturgeschichte teil. Im Laufe der drei Workshoptage wurden methodologische Probleme innerhalb und außerhalb der eigenen Projekte identifiziert und hierfür Lösungsansätze entwickelt.
Ziel der vorliegenden Blogpostreihe »Digital Humanities« mit ihren fünf Beiträgen zu Fachdisziplinen, Methodenbewusstsein, Transparenz, Nachhaltigkeit und Best practices ist es, diese Lösungsvorschläge zu sammeln und damit best practices für die Arbeit mit digitalen Werkzeugen und Methoden in den Geisteswissenschaften vorzuschlagen. Diese sollen es anderen Wissenschaftler_innen erleichtern, künftige Forschungsprojekte von Anfang an methodisch stringent zu konzipieren.
Am Anfang einer jeden Studie steht eine Forschungsfrage und eine daran angeschlossene methodologische Vorüberlegung. In unserer Erfahrung haben wir jedoch festgestellt, dass die grundlegende Reflexion der Wahl der Methode und deren Wechselwirkung mit der Forschungsfrage sowie deren Eignung in den Digital Humanities einer gewissen Schwankungsbreite unterliegt. Es fehlt an manchen Stellen ein Bewusstsein dafür, dass die Digital Humanities kein methodenfreier Raum sind. So werden häufig digitale Werkzeuge und Methoden herangezogen, bevor deren Nutzen im konkreten Fall bewertet wurde.
DIGITAL ≠ BESSER Der Einsatz digitaler Mittel alleine schafft keinen Mehrwert in sich, daher ist dieser in die herkömmliche Methodenüberlegung einzubeziehen. Hierbei sollte vor allem die Frage gestellt werden: Arbeitet man um der Daten willen oder lässt man die Daten für sich arbeiten? Es sollte sichergestellt sein, dass der Einsatz von Datenbanken, Annotationen oder digitalen Corpora letztendlich nicht zu einem vermeidbaren Mehraufwand ohne nennenswerten Erkenntnisgewinn führt.
DAS RICHTIGE WERKZEUG FÜR DIE AUFGABE Es ist ebenso in die methodische Reflexion einzubeziehen, welche Technologien zur Verfügung stehen und welche Vor- und Nachteile diese mit sich bringen. Während in der Editionsphilologie bspw. Annotationen und Publikationen in XML ein anerkannter Standard sind, gibt es andere Herangehensweisen wie z.B. SQL-Datenbanken, die für andere Fragestellungen besser geeignet sind. Vor allem zur Darstellung komplexer Strukturen, Beziehungsgeflechte und Netzwerke sind solche Datenbanken u.U. besser geeignet als XML.
Die Wahl der richtigen Technologie ist nicht unerheblich. Um im Beispiel zu bleiben: XML und SQL repräsentieren gänzlich unterschiedliche Herangehensweisen an die Modellierung und Strukturierung von Daten. Für Forschungsfragen, die einen hohen Anteil statistischer Berechnungen erfordern, sind SQL-Datenbanken weit besser geeignet, während XML sehr viel mehr Freiheiten in Bezug auf Datenstrukturen bietet. Dies führt letztlich zu unterschiedlichen konzeptuellen Darstellungen des Forschungsgegenstandes und hat damit direkte Auswirkungen auf die Forschungsfrage bzw. deren Beantwortung. Frage und Methode beeinflussen sich für gewöhnlich wechselseitig. Jedoch sollten die Grenzen einer Technologie nicht die Forschungsfrage deformieren. Die Entscheidung, das eine Werkzeug dem anderen vorzuziehen, sollte nicht auf der Basis getroffen werden, womit man vertrauter ist, sondern welches Werkzeug die entsprechenden Funktionen bietet, um die Forschungsfrage beantworten zu können. Eine Reflexion dieses Verhältnisses ist also unbedingt geboten, vor allem, weil sie nicht immer selbstverständlich scheint.
DER FORSCHUNGSGEGENSTAND VS. SEINE DIGITALE REPRÄSENTATION Auch die konkrete Strukturierung der Forschungsdaten sollte kein positivistisches Unterfangen sein und sollte ebenso kritisch betrachtet werden wie der Forschungsgegenstand selbst. Die methodisch-theoretischen Überlegungen, welche einer jeden Studie zu Grunde liegen, sind in gleicher Weise auf die Modellierung der Forschungsdaten auszudehnen und anzuwenden. Es muss also reflektiert werden, in welcher Form die Forschungsdaten den Forschungsgegenstand möglichst adäquat repräsentieren. Hierbei ist zunächst eine wichtige Unterscheidung zu machen: Es ist zwischen der abstrakten Struktur der Informationen und deren Inhalt zu trennen. Diese Trennung beinhaltet auch die konzeptionelle Trennung zwischen dem Forschungsgegenstand selbst und dessen digitaler Repräsentanz. Für eine stringente Umsetzung der Repräsentanz eines Forschungsgegenstandes ist die konsequente Anwendung und Dokumentation der Terminologie unerlässlich. Idealerweise wird auf eine etablierte und geeignete Ontologie zurückgegriffen, wie z.B. CIDOC CRM und deren Derivate. Hierbei ist der Kohärenz der digitalen Repräsentation Vorrang vor einer linearen Abbildung des Forschungsgegenstandes zu geben. Sollen beispielsweise die Wörter eines Textes erfasst und eindeutig identifiziert werden, ist zwischen den Wörtern auf der Seite und den Wörtern im Computer zu unterscheiden. Die Integrität des gewählten Modus der Zuordnung hat unbedingten Vorrang: Stellt sich so heraus, dass ein Wort in einer Transkription nicht beachtet wurde und wird dieses später hinzugefügt, darf keinesfalls die ID der umliegenden Wörter geändert werden. Vielmehr muss das nun eingeschobene Wort eine ID aus der fortlaufenden Reihe erhalten, da sonst alle Verweise auf nachfolgende Wörter nicht mehr korrekt sind und ggf. ebenfalls händisch korrigiert werden müssen. Dies ist nicht nur zeitaufwändig und fehleranfällig, es erschwert auch die Zitierbarkeit des betreffenden Corpus erheblich.
Ein praktisches Beispiel dazu aus einem der Projekte der Workshopteilnehmer_innen: Die physische Realität vieler Runeninschriften sieht so aus, dass Teile der Inschrift entweder in unterschiedliche Bestandteile z.B. einer Brosche, oder, im Falle einer Runeninschrift auf Holz oder Knochen, in eine oder mehrere Seiten des physischen Objektes geritzt worden sind. Diese physische Realität sollte in einer Datenbank abgebildet werden. Dies kann beispielsweise folgendermaßen aussehen:
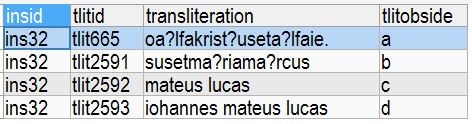
Wie in der Abbildung zu sehen ist, ist jeder der vier Seiten der Inschrift (a-d, Feld tlitobside) jeweils ein eigener primary key (tlitid) zugeteilt worden. Dass es sich dabei um vier Seiten derselben Inschrift handelt, wird über den Inhalt des Feldes insid klar, das für alle vier tlitids denselben Wert anzeigt. Das Feld transliteration gibt die jeweilige Lesung der Runen auf der betreffenden Seite in lateinischen Buchstaben wieder, während das letzte Feld, tlitobside, die in der Runologie übliche Nummerierung unterschiedlicher Seiten eines physischen Objektes mit lateinischen Kleinbuchstaben beinhaltet. Auf diese Art und Weise kann, wenn in der Datenbank unterschiedliche Lesungen enthalten sind, ein direkter Vergleich angestellt werden, welcher Forscher welche Seite der Inschrift wie transliteriert hat. Wie die primary keys zeigen, sind die Seiten b bis d erst später als eigene Einträge hinzugefügt worden; ursprünglich waren alle vier Seiten unter tlit665 zusammengefasste. Dies führte zu erheblichen Problemen in der Arbeit mit der Datenbank, und es zeigte sich, dass die Abbildung der physischen Realität (eine Inschrift, vier Seiten) der ursprünglichen Struktur vorzuziehen ist. Da die Zugehörigkeit zu einer Inschrift sowie die Lesereihenfolge der vier Seiten durch die Felder insid/tlitobside angegeben wird, ist es auch irrelevant, dass die tlits nicht fortlaufend nummeriert sind.
AMBIGUITÄT IN 0 UND 1 Des Weiteren ist auf dieser Grundlage zu reflektieren, wie ein Computer mit Ambiguitäten umgeht. Da Computersysteme auf binärer Basis operieren, sind sie darauf in erster Linie nicht ausgerichtet. Es ist also Aufgabe der Geisteswissenschaften, sich die Ambiguität, welche ein elementarer Bestandteil geisteswissenschaftlichen Denkens und Arbeitens ist, zu bewahren. Ein unreflektierter Einsatz von Datenbanksystemen u.ä. läuft Gefahr, Ambiguität zu Gunsten von Strukturen zu opfern. Es ist also unerlässlich, in die Überlegungen zur Datenmodellierung mit einzubeziehen, wie sich Ambiguität abbilden, reflektieren und für das Erkenntnisinteresse nutzen lässt.
Methodenbewusstsein in den Digital Humanities erfordert, dass man sich sowohl der Begrenzungen als auch der Möglichkeiten der verschiedenen Technologien bewusst ist und dass man darüber reflektiert, wie das gewählte Werkzeug oder die gewählte Struktur auf die Forschungsfrage und ihre Beantwortung(en) einwirkt. Zur Frage, wie man mit Ambiguitäten in einem bis in seine kleinsten Bausteine eindeutigen Format umgeht, und wie man sie bewahrt – oder nicht bewahrt –, werden wir im nächsten Blogpost über Transparenz in den Digital Humanities zurückkehren.
Übersicht Blogbeiträge der Reihe »Wissenschaftliche Prinzipien in den Digital Humanities«
Teil 1: Wissenschaftliche Prinzipien in den Digital Humanities: Digital Humanities und die Fachdisziplinen
Teil 2: Wissenschaftliche Prinzipien in den Digital Humanities: Methodenbewusstsein
Teil 3: Wissenschaftliche Prinzipien in den Digital Humanities: Transparenz in den Digital Humanities
Teil 4: Wissenschaftliche Prinzipien in den Digital Humanities: Nachhaltigkeit in den Digital Humanities
Teil 5: Wissenschaftliche Prinzipien in den Digital Humanities: Best practices
Über die Autor_innen der Blogpostreihe
Elisabeth Maria Magin, PhD war bis 2021 Doktorandin an der University of Nottingham mit Anbindung an der Universität Bergen, wo die Runeninschriften gelagert sind, welche die Grundlage für ihre runologische Datenbank bilden. In ihrer Doktorarbeit hat sie untersucht, wie SQL-basierte Datenbanken dazu genutzt werden können, größere Korpora von Runeninschriften im Hinblick auf die soziale Identität der Runenritzer zu analysieren.
Ingrid M. F. Heiene ist Doktorandin an der NTNU – Technisch-Naturwissenschaftliche Universität Norwegens, und untersucht Entwicklungen in Nominalphrasensyntax, Kasusmorphologie und Bestimmtheitsmorphologie in mittelnorwegischen Diplomen aus einem generativen Standpunkt.
Balduin Landolt studierte in Basel und Reykjavik Skandinavistik und Germanistik, derzeit plant er ein Doktorat zur digitalen Erschließung komplexer handschriftlicher Textüberlieferungen. Daneben arbeitet er als Software Developer beim Data and Service Center for the Humanities (DaSCH) in Basel.
Sven Kraus studierte Skandinavistik und European Studies an der Humboldt-Universität zu Berlin, der Universität Bergen und der Europa-Universität Viadrina Frankfurt (Oder). Seit September 2019 promoviert er in Basel zu Übersetzung und Kulturtransfer im Nordwesteuropa des 13. Jahrhunderts und verbindet dabei philologische Betrachtungsweisen mit experimentellen Ansätzen der Digital Humanities.